Target identification in biotech, formally called drug target identification, is the process of pinpointing the specific biological molecule whose modulation will produce a desired therapeutic effect. It is the first and most critical step in drug discovery, shaping every decision that follows, from screening strategy to clinical design. Most programs that fail in Phase II or Phase III can trace their failure back to a weak target hypothesis. Getting this step right is not a matter of intuition. It requires layered, multi-modal evidence and a clear understanding of what "right" actually means in a biological context.
Table of Contents
- Key Takeaways
- What is target identification in biotech
- Advanced experimental techniques for target identification
- Practical considerations for choosing your strategy
- Emerging trends shaping target identification
- My perspective on what actually works
- How Innovabiotech supports your target identification work
- FAQ
Key Takeaways
| Point | Details |
|---|---|
| Target ID is foundational | Every downstream drug development decision depends on the quality of your initial target hypothesis. |
| Single datasets are insufficient | No one data type fully captures causality; convergent genetic, omics, and functional evidence is required. |
| Experimental and computational methods must converge | Techniques like CETSA, TPP, and Cell Painting work best when combined, not used in isolation. |
| Target context drives strategy | Assay readiness, structural data, and druggability determine which screening approach fits your target. |
| AI supplements expert judgment | AI accelerates target exploration and validation but cannot replace mechanistic interpretation by experienced researchers. |
What is target identification in biotech
Drug target identification is the systematic process of determining which protein, gene, RNA, or other biological entity is causally linked to a disease state and can be modulated to achieve a therapeutic outcome. The word "causally" carries significant weight here. A molecule that correlates with disease is not the same as one that drives it, and confusing the two is one of the most common and costly mistakes in early drug discovery.
Biological targets span several molecular classes:
- Proteins (enzymes, receptors, ion channels, transporters): the most common and historically tractable class
- Nucleic acids (DNA, mRNA, non-coding RNA): increasingly relevant for gene silencing and editing approaches
- Protein-protein interactions: challenging to drug but clinically significant in oncology and inflammation
- Lipids and metabolites: emerging targets in metabolic disease and the microbiome space
The biotech target discovery process draws on genetics, transcriptomics, proteomics, functional genomics, and clinical data simultaneously. No single dataset fully captures causality or therapeutic relevance. This is why convergent evidence, meaning agreement across multiple independent data types, has become the standard for advancing a target hypothesis into formal development.
Pro Tip: Before committing to a target, ask whether you have at least three independent lines of evidence supporting causality. Genetic association alone, even from a well-powered GWAS, is rarely sufficient without mechanistic and functional corroboration.
The target identification process also feeds directly into modality decisions. If your target is an intracellular enzyme with a well-defined active site and available crystal structures, small molecules are a natural fit. If the target is a disordered protein or a protein-protein interface, you may be looking at peptide design or biologics from the start. Getting the target right means getting the modality right, and that shapes your entire chemistry and biology program.
Advanced experimental techniques for target identification
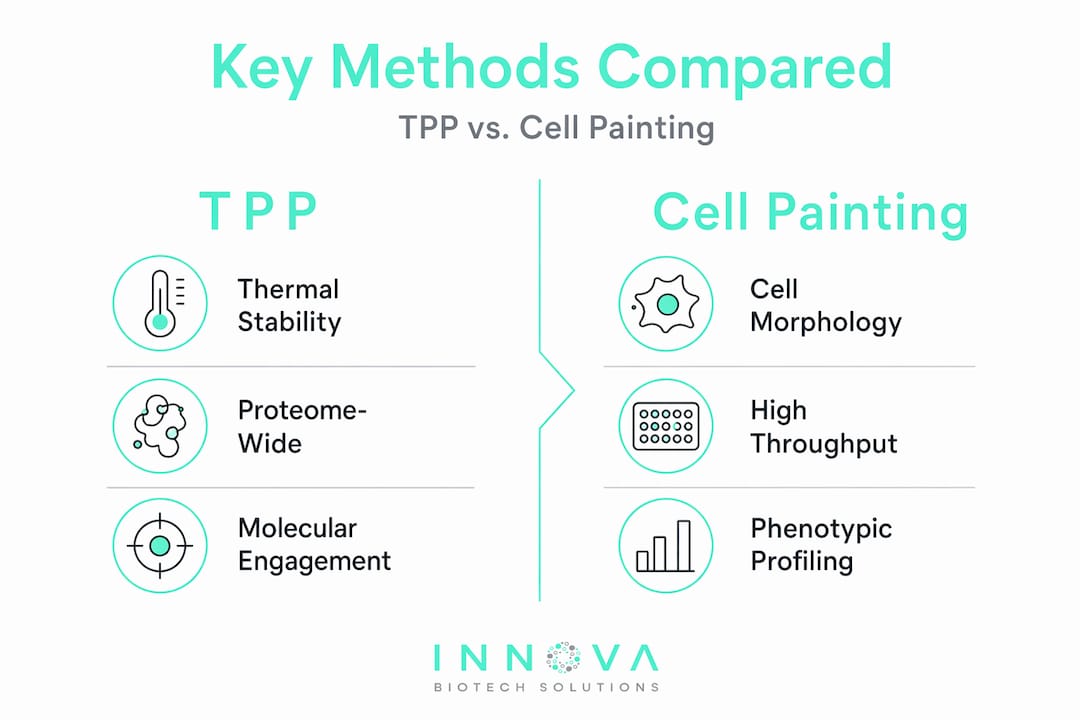
Once a target hypothesis exists, experimental confirmation requires methods that can detect direct molecular engagement inside biologically relevant systems. Two techniques have become central to modern target identification workflows: Cellular Thermal Shift Assay (CETSA) and Thermal Proteome Profiling (TPP).

CETSA measures changes in a protein's thermal stability upon compound binding. When a small molecule binds its target, it typically stabilizes the protein against heat-induced denaturation. TPP extends this concept proteome-wide, applying mass spectrometry to detect thermal stability changes across thousands of proteins simultaneously. TPP often detects tens to hundreds of thermally shifted proteins, which means follow-up experiments are required to distinguish direct binding from indirect network effects.
Comparing key target identification methods
| Method | What it measures | Strength | Key limitation |
|---|---|---|---|
| CETSA | Single protein thermal stability shift | Direct target engagement in cells | Low throughput; requires prior target hypothesis |
| TPP | Proteome-wide thermal stability changes | Unbiased, hypothesis-free discovery | Many indirect hits; requires orthogonal confirmation |
| Cell Painting | Morphological cell phenotype profiling | Captures mechanism of action signatures | Indirect; needs pairing with molecular data |
| Affinity capture/chemoproteomics | Compound-binding protein pulldown | Direct physical interaction evidence | Requires cell-permeable, modifiable probe compounds |
The most productive approach in 2026 combines TPP with Cell Painting morphological profiling. Integrating Cell Painting with TPP narrows candidate targets substantially compared to either method used alone, because morphological signatures constrain the biological interpretation of proteome perturbation data. A compound that shifts 80 proteins thermally but produces a phenotype consistent with mitochondrial disruption immediately focuses your attention on the mitochondria-associated subset of those 80 proteins.
The back-translation framework adds another layer of precision. By integrating clinical trial and biobank genetic data, researchers can map phenotypic observations in patients back to molecular hypotheses, then test those hypotheses experimentally. This approach bridges the gap between population-level signals and mechanistic biology, which is exactly where many programs historically lost confidence in their target.
Pro Tip: In TPP workflows, plan your orthogonal assays before you run the experiment. Dose-response thermal shift, time-course studies, and direct binding confirmation should be pre-specified. Retrofitting these experiments after seeing data introduces selection bias.
Practical considerations for choosing your strategy
Choosing how to identify and validate a target is not a one-size-fits-all decision. Target context including assay readiness, structural information, druggability, and the IP landscape determines which experimental route makes sense. Here is a practical decision workflow:
-
Assess structural and biochemical data availability. If crystal structures or cryo-EM data exist for your target, virtual screening and structure-based drug design become viable from day one. Without structural data, biochemical or cell-based phenotypic approaches take priority.
-
Evaluate assay readiness. Can you measure target activity directly? A robust biochemical assay enables high-throughput screening (HTS) and fragment-based discovery. If no direct assay exists, you will need a cell-based or phenotypic surrogate, which increases the complexity of target deconvolution later.
-
Determine druggability. Enzymes and GPCRs have established druggability precedent. Transcription factors and scaffolding proteins are harder. If druggability is uncertain, invest in computational druggability prediction and structural analysis before committing to a chemistry program.
-
Map the IP landscape. A target with saturated IP may require a differentiated binding site or modality to produce protectable chemistry. Knowing this early prevents wasted medicinal chemistry effort.
-
Design for deconvolution from the start. In phenotypic programs, separating direct targets from downstream effects requires robust controls and complementary experiments built into the study design, not added after the fact.
A common pitfall is advancing a target based on genetic association without mechanistic assignment. Causal target selection from genetics requires pathway and mechanism refinement beyond the gene-locus association itself. The GWAS hit points to a region; the biology tells you which gene in that region, and in which cell type, and through which mechanism.
Pro Tip: If your target lacks a direct biochemical assay, use orthogonal cell-based readouts that measure the same biology through different mechanisms. Agreement across two independent cell-based assays is a meaningful signal; a single readout is not.
Emerging trends shaping target identification
The field is moving fast. Several trends are reshaping how researchers approach the steps in target identification and what counts as sufficient evidence to advance.
-
AI-driven network analysis. AI enhances target exploration by processing biological network data at a scale no human team can match. Machine learning models trained on multi-omics data are identifying non-obvious target candidates, including some that have now entered clinical trials. Platforms using cognitive BioLLMs are extending this capability into peptide target space specifically.
-
Multi-omics integration for precision medicine. Single-cell transcriptomics, spatial proteomics, and epigenomics are being layered together to understand target expression and function at the cell-type level. This matters because a target expressed broadly across tissues carries a very different risk profile than one expressed only in the disease-relevant cell population.
-
Patient-derived and clinical data integration. The back-translation framework, bridging phenotypic and molecular information from biobanks and clinical trials, is becoming standard practice in precision oncology and rare disease programs. It shifts target discovery from purely preclinical models toward human-validated biology.
-
Improved phenotypic deconvolution tools. New chemoproteomics reagents and improved mass spectrometry sensitivity are making it possible to identify targets for compounds that were previously intractable, particularly those with covalent or allosteric mechanisms.
-
Validation challenges for AI-generated hypotheses. AI can propose targets faster than experimental teams can validate them. The bottleneck is shifting from hypothesis generation to hypothesis testing, which means experimental throughput and orthogonal assay design are becoming competitive differentiators.
My perspective on what actually works
I have seen programs invest heavily in computational target prediction, generate a compelling list of candidates, and then struggle for two years because nobody asked whether those targets were actually assayable in a relevant biological system. The biology was interesting. The targets were not workable.
What I have learned is that the importance of target identification is not just about picking the right molecule. It is about building a case that will survive contact with reality. That means multi-layered evidence, not a single impressive dataset. It means designing your deconvolution strategy before you run your phenotypic screen, not after you see a hit you want to believe in. And it means being honest about what thermal shift data can and cannot tell you. Proteins in complexes or pathway members may show thermal shifts with no relationship to direct binding, and I have watched teams chase those signals for months.
My honest take on AI in this space: it is genuinely useful for hypothesis generation and for prioritizing among candidates when you have rich multi-omics data. It is not a substitute for a researcher who understands the disease biology deeply enough to know which hypothesis is biologically plausible versus statistically convenient. The best programs I have seen treat AI output as a starting point for expert interrogation, not as a conclusion.
The teams that minimize late-stage failures are the ones that invest in rigorous early validation, accept negative data as informative, and resist the pressure to advance a target because the timeline demands it. That discipline is harder than any assay.
— Hooman
How Innovabiotech supports your target identification work
When you are working through a target identification program, the gap between a promising hypothesis and a validated, workable target is where most resources disappear. Innovabiotech was built to close that gap.

Our team in San Francisco supports researchers at every stage of early discovery, from computational target prioritization to experimental validation support. For targets where structural data is available, our virtual screening services accelerate hit identification against your confirmed target. Where the target is a protein requiring engineering for assay development, our protein design capabilities provide computational modeling and chimeric construct design. For programs where peptides are the right modality, our peptide design services integrate binding affinity prediction with bioinformatics validation to move from target to lead faster. We also offer enzyme optimization solutions for targets in metabolic and catalytic biology. Every engagement starts with a direct conversation about your target context, not a generic service menu.
FAQ
What is target identification in drug discovery?
Target identification is the process of determining which specific biological molecule, typically a protein, gene, or RNA, is causally linked to a disease and can be modulated to produce a therapeutic effect. It is the foundational step that shapes all subsequent drug development decisions.
What are the main target identification methods?
The primary methods include CETSA, thermal proteome profiling (TPP), affinity-based chemoproteomics, functional genomics screens, and phenotypic deconvolution. Modern programs combine multiple approaches because no single method provides sufficient evidence of direct target engagement on its own.
Why does target identification matter so much for drug discovery success?
Target identification is a safety and efficacy decision that determines every downstream stage of development. Programs built on weak target hypotheses tend to fail in late-stage clinical trials, where failure is most expensive and most damaging.
How does AI improve the target identification process?
AI analyzes large biological networks and multi-omics datasets to identify non-obvious target candidates and prioritize among them. Several AI-identified targets have now entered clinical trials, though AI output still requires expert mechanistic validation before a program commits resources.
What is the difference between target identification and target validation?
Target identification establishes which molecule is linked to disease. Biotechnology target validation confirms that modulating that molecule produces the expected biological effect in relevant models and that the target is sufficiently druggable to support a chemistry program. Both steps are required before advancing to hit identification.